
4 Best AI Text-to-Speech Services in 2026
Text-to-speech has gotten good enough that it is no longer just an accessibility feature or a novelty. If you are building an AI app, voice agent, audiobook tool, customer support bot, or content workflow, your TTS provider now has a huge impact on how polished the final product feels.
In this post, I am comparing four of the best TTS services worth considering right now:
How I Am Comparing Them
For this comparison, I want to look beyond just “which one sounds best.” Voice quality matters, but the best TTS service depends on what you are building.
I’ll be measuring these criteria:
- Overall voice quality: How natural, clear, and human the generated speech sounds.
- Latency: How quickly audio starts and finishes generating.
- Customization: How easy it is to customize the voice and speech style.
- Pricing: Cost per character, token, minute, or request, plus how predictable it is at scale.
For each criterion, I’ll assign a score from 1 to 5, with 5 being the best. I’ll be testing the TTS models on their native platforms and in AgentOne.
1. OpenAI
I tested OpenAI’s latest TTS model, GPT-4o mini TTS, on their official site, https://www.openai.fm/. There are 13 voices available.
This TTS model works with an input, which is the text you want to convert to speech, and instructions, where you can tell the model how to speak it. Instructions are very useful for customizing how the voice sounds - for example, you can tell the model to speak faster or slower, or express a certain emotion or tone.
Here are a couple of samples:
Sarcastic (Male):
Actioneer (Female):
As far as latency, it does take a bit longer to generate audio compared to other services. Pricing details are a bit confusing. It looks like the model costs $12.00 per 1 million output audio tokens, with text input costing $0.60 per token. You can find the details here: https://developers.openai.com/api/docs/pricing
2. ElevenLabs
I tested ElevenLabs’ newest model, v3, on https://elevenlabs.io/app/speech-synthesis/text-to-speech. It’s honestly really impressive! I think it’s more realistic than OpenAI, though you style the voice by including instructions inline as brackets, for example [whispering] What is that noise? [screaming] Ah, a ghost!.
The voice quality is great, the expressiveness is great, and the latency is acceptable.
Here’s a sample audio output:
The pricing is pretty straightforward. For the latest pricing details, visit https://elevenlabs.io/pricing/api. You’re billed per character - as of the time of writing, 1000 characters cost $0.05 with the Flash model. I think this is more expensive than OpenAI, but it’s still a great option.
3. LMNT
What really stood out to me with LMNT was how fast it is. The audio begins streaming so quickly! I tested LMNT in AgentOne and on their website at https://app.lmnt.com/. Both LMNT and ElevenLabs support voice cloning, but I found it to be a smoother experience on LMNT. At the time of writing, there are 24 built-in voices and a generous free tier. The voice expressiveness and quality are okay, but not as good as ElevenLabs or OpenAI in my opinion. Here are some samples:
Male Voice:
Female Voice:
Pricing is simple. Check out https://www.lmnt.com/pricing for the full details.
4. Hume
Hume is a great general-purpose TTS service. The voices are expressive and natural, though they sometimes struggle or pronounce words incorrectly. Many voices are available (too many to count!). Rather than passing instructions to the model, the model relies on context to determine how to read your input aloud. This is a cool approach, but it does have downsides, and I found it harder to customize the voices compared to ElevenLabs for example. Hume is pretty fast. It also has a free tier. More details are available on their website, here: https://www.hume.ai/pricing
Two samples:
Male English Actor:
Female Voice:
Rankings
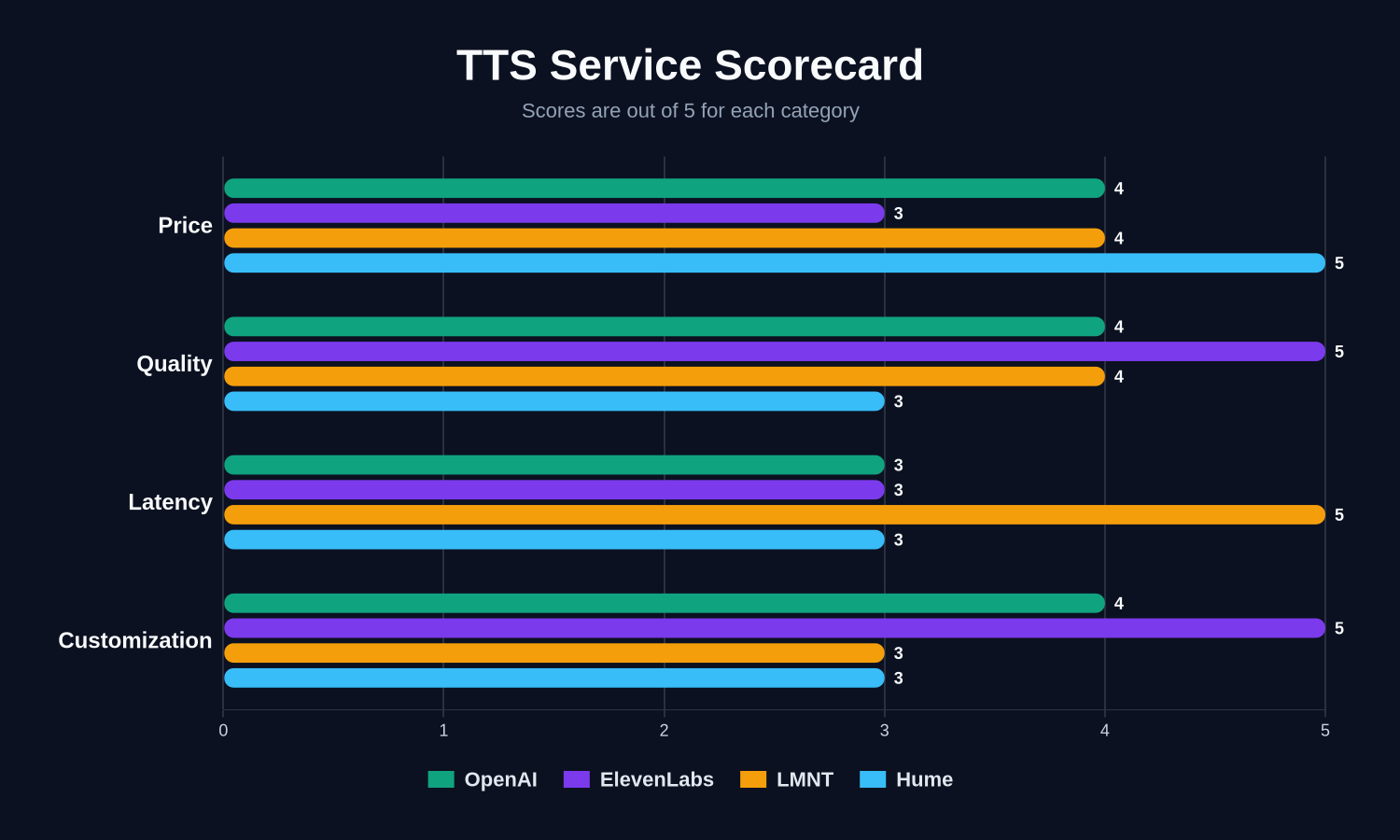
Best overall: ElevenLabs
ElevenLabs has the highest ceiling for voice quality and customization. It is not the cheapest option, and its latency is not the fastest in this group, but if the final audio needs to sound polished, expressive, and production-ready, ElevenLabs is my top pick.
Best for low latency: LMNT
LMNT ties ElevenLabs on total score, but it wins the latency category clearly. If you are building a voice agent, conversational interface, or any product where response time matters, LMNT is the easiest recommendation. The tradeoff is that customization and expressiveness are not quite as strong as ElevenLabs.
Best developer-friendly general option: OpenAI
OpenAI is the most balanced option here. The quality is strong, the pricing is competitive, and the instruction-based customization model is convenient if you already use OpenAI APIs. I would choose OpenAI when I want solid TTS without adding another specialized provider.
Best budget pick: Hume
Hume scores best on price and has a generous free tier, which makes it a good option for experiments, prototypes, and projects where cost matters most. The main downside is control: the context-driven style system is interesting, but I found it less predictable than direct instructions or voice settings.
That’s all for now! Thanks for reading.